风影古文典籍全文检索系统是由我工作室独立开发完成并已实际应用的项目,该项目中涉及到将海量数据采用目录树结构的方式呈现出来,类似于windows资源管理器的目录树结构。由于要在浏览器中使用,因此需要考虑到目录树生成脚本的性能问题。此外,该目录树初始化时仅呈现有限级别的层级结构(比如需呈现所有分类信息,并加载到书籍结点),这是为了尽可能的在优化网络传输的数据量同时也不损失加载性能;但是,为了提供更好的用户体验,当用户在展开书籍节点时,该目录树又需要呈现进一步详细的信息(如章节信息),直至显示到文章的标题信息为止,这就需要动态加载和处理相应的数据了。最后,在该系统的使用过程中,在用户检索到目标后还需要能对目录树中的相应结节进行定位以方便查阅,而无需用户手工去展开和查找。
常规的目录树js脚本生成代码由于性能原因基本不予考虑(一般在节点数达到1000以上的数量级时,这些脚本的执行性能往往呈级数下降,容易导致浏览器假死)。.net自带的TreeView控件冗余代码过多,灵活性较差且加载效率低下,因此也没有考虑。经过反复测试和筛选,最终我们决定采用改写的梅花雪树MzTreeView脚本插件来生成目录树,梅花雪树的数据是一次性加载,支持页面数据的异步传输和处理,并且不需要递归绑定数据。它的数据有其特定的结构要求,类似于data["A_B"] = "text: ABC";的结构,其异步通信的数据也是类似的结构,不过要注意通信编码的格式要与页面数据编码格式一致,否则会出现无响应或乱码等情况。 首页需要引入梅花雪树的脚本文件:<script type="text/javascript" language="javascript" src="JS/jsframework.js"></script>,然后是绑定数据项,我们设计了一个单独的控件来生成数据项,其render事件代码如下:
protected override void Render(HtmlTextWriter output)
{
StringBuilder builder = new StringBuilder();
builder.Append("<script language='JavaScript'>");
builder.Append("var data={};\n");
IList list = SysManage.ReadClassList();
using (IEnumerator enumerator = list.GetEnumerator())
{
while (enumerator.MoveNext())
{
ClassInfo info = enumerator.Current;
string str = string.Empty;
builder.Append("data['" + info.FatherID + "_" + info.ID + "'] = 'text:" + info.ClassName
+ ";url:javascript:void(0);;';\n");
IList bookList = SysManage.ReadBookList(info.ID);
using (IEnumerator enumerator2 = bookList.GetEnumerator())
{
while (enumerator2.MoveNext())
{
BookInfo bookInfo = enumerator2.Current;
string srcStr = "BookView.aspx?BookID=" + Filter.Encode(bookInfo.ID.ToString());
builder.Append("data['" + info.ID + "_BOOK" + bookInfo.ID + "'] = 'text:" + bookInfo.BookName
+ ";icon:book;url:" + srcStr + ";target:right;JSData:JSArticle.aspx?BookID="
+ Filter.Encode(bookInfo.ID.ToString()) + "';\n");
}
}
}
}
builder.Append("Using(\"System.Web.UI.WebControls.MzTreeView\");\nvar a = new MzTreeView();\n
a.dataSource = data;\na.canOperate=true;\na.autoSort=false;\na.useCheckbox=true;\ndocument.write(a.render());\n
a.expandLevel(1);");
builder.Append("</script>");
output.Write(builder.ToString());
}
这里尽管书籍分类数据是多层级的结构,但在绑定数据的过程中完全不需要采用递归的方法,直接循环就可以生成数据项了,这里对服务器端的性能有较大的提升。以上代码中,由于书籍数据是可以在页面访问的,因此在数据项中绑定了访问链结地址。另外,对于书籍的详细章节及文章信息,在初始化时并非同时生成(由于数据传输量限制及性能等原因),因此采用Ajax技术通过异步交互的方式来获取,这里也同时绑定了书籍详细信息的获取链结。需要注意的是,为了避免信息交互过程中采用默认编码方式可能出现的错误,这里对参数都进行了统一编码。最后,我们通过改写脚本实现了自定义的图标显示模式。当数据项绑定完成后,就可以实例化对象生成目录树了,这里通过将useCheckbox属性设置为true以启用复选框功能,下面将对此功能的使用作进一步的讨论。
前面提到异步交互获取书籍详细信息的页面,其逻辑处理代码如下:
StringBuilder builder = new StringBuilder("var data={};\n");
IList chapterList = SysManage.ReadChapterList(bookID);
IList artList = SysManage.ReadArticleList(bookID, 0);
using (IEnumerator enumerator1 = artList.GetEnumerator())
{
while (enumerator1.MoveNext())
{
ArticleInfo artInfo = enumerator1.Current;
string artStr = "ArticleDetail.aspx?ID=" + Filter.Encode(artInfo.ID.ToString());
builder.Append("data['BOOK" + bookID + "_ARTICLE" + artInfo.ID + "'] = 'text:"
+ artInfo.ArticleTitle.Trim() + ";url:" + artStr + ";target:right;';\n");
}
}
using (IEnumerator enumerator = chapterList.GetEnumerator())
{
while (enumerator.MoveNext())
{
ChapterInfo cptInfo = enumerator.Current;
builder.Append("data['BOOK" + bookID + "_CHAPTER" + cptInfo.ID + "'] = 'text:"
+ cptInfo.ChapterTitle.Trim() + ";icon:chapter;url:javascript:void(0);';\n");
IList cptArtList = SysManage.ReadArticleList(bookID, cptInfo.ID);
using (IEnumerator enumerator1 = cptArtList.GetEnumerator())
{
while (enumerator1.MoveNext())
{
ArticleInfo artInfo = enumerator1.Current;
string artStr = "ArticleDetail.aspx?ID=" + Filter.Encode(artInfo.ID.ToString());
builder.Append("data['CHAPTER" + cptInfo.ID + "_ARTICLE" + artInfo.ID + "'] = 'text:"
+ artInfo.ArticleTitle.Trim() + ";url:" + artStr + ";target:right;';\n");
}
}
}
}
HttpContext.Current.Response.ClearContent();
HttpContext.Current.Response.ContentType = "text/javascript";
HttpContext.Current.Response.Charset = "UTF-8";
HttpContext.Current.Response.ContentEncoding = System.Text.Encoding.UTF8;
HttpContext.Current.Response.Write(builder.ToString());
HttpContext.Current.Response.End();
}
这里针对书籍可能包含章节信息以及文章详细信息的内容进行了处理,同样采用循环的方式读取信息并以章节或文章的个性化图标进行显示,交互的数据采用UTF-8编码,采用javascript脚本及梅花雪树的数据格式反馈数据。以古文典籍检索系统测试数据生成的目录树如图:
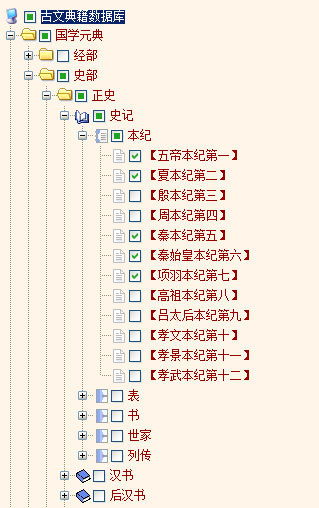
在前台页面,对包含上述目录树控件的层添加一个onclick的事件响应脚本,<div id="info" onclick="saveChecked(a);"><SrchSys:ClassTree ID="ClassTree1" runat="server" /></div>,传递的参数即为实例化的梅花雪树。脚本的处理代码如下:
function getChecked(a) {
var classStr = "";
var bookStr="";
var articleStr="";
var chapterStr="";
var classIDField=document.getElementById("ClassIDField");
var bookIDField = document.getElementById("BookIDField");
var articleIDField=document.getElementById("ArticleIDField");
var chapterIDField=document.getElementById("ChapterIDField");
for (var i in a.nodes) {
if (a.nodes[i].checked&&a.nodes[i].parentNode!=null&&!(a.nodes[i].parentNode.checked)){
if(a.nodes[i].id.indexOf("BOOK")!=-1) bookStr += a.nodes[i].id.substr(4,a.nodes[i].id.length-4) + ",";
else if(a.nodes[i].id.indexOf("ARTICLE")!=-1) articleStr+=a.nodes[i].id.substr(7,a.nodes[i].id.length-7) + ",";
else if(a.nodes[i].id.indexOf("CHAPTER")!=-1) chapterStr+=a.nodes[i].id.substr(7,a.nodes[i].id.length-7) + ",";
else classStr += a.nodes[i].id+",";}
}
}
这里综合了梅花雪树对节点的选取及对id值属性的读取方法来得到所选择项的分类数据、章节数据及文章数据,然后保存在隐藏对象中,在用户提交时再传递到后台做筛选或其它处理。这里实现该功能的一个前提是在目录树的构造过程中传递相应结构的参数以生成id,这也是为什么前述的数据项的格式分别以BOOK,ARTICLE,CHAPTER等方式命名的原因。
最后再谈谈目录树结点的定位,典型的应用即是当用户检索到书籍或文章数据后,通过定位功能可以直接在目录树中展开并定位到相应的节点,效果如图。

这一功能实现起来并不复杂,通过与梅花雪树的节点定位功能相结合,在后台生成访问数据链,在前台通过脚本定位即可。前台代码如<a title="在目录树中定位展开" href='javascript:focusNode("<%=SysManage.ReadBookPath(Data.Rows[i]["ID"])%>");'>目录定位</a>。后台代码如下:
public static string ReadBookPath(int BookID)
{
string retStr = "";
BookInfo info = SysManage.ReadBookInfo(BookID);
if (info != null)
{
using (DataProvider dp = new DataProvider())
{
retStr = SysDataProvider.ReadClassPath(info.ClassID) + "_BOOK" + BookID.ToString();
}
}
return retStr;
}
相应的,对于文章的数据也可以采用类似方法定位。至此,我们就完成了一个高效目录树的数据绑定,动态加载,交互,定位等功能。
世界末日了哈!!!在这世间最后一天的时候,我们希望能给后人留下点什么(以便于考古研究),这便是写本篇技术文章的初衷。^_^
(注:本文为 [风影网络工作室] 原创文章,未经书面许可,严禁转载和复制本站的任何信息,违者必究)